前言
今年有为一家公司利用不到一个月了解数据的现状,做了些整理和规划,隐去一些必要信息外,提供一些模版做参考。
数据工程技术建设
背景
随着公司的业务交付越来越多,不论是接触的数据领域以及近年来的数据数量大小本身也都是在快速的增长,如何针对数据处理的各个环节进行管理管控,同时设计一个可扩展的数据架构,以满足未来业务的诉求,最终目标是大家能够达到业务与技术的统一认识。
当前处理流程
(略)
问题部分摘取:
- 代码脚本化,非工程化,没有设计模式,代码冗余,公用方法无法沉淀
- 没有或部分应用gitlab等代码版本管理工具,无法回溯定位问题
- 对共性代码或者字典集硬code,需要统一编码管理,也包括属性的配置化
- 采集实现,有scrapy的,大多是request实现,不利于继承,统一实现框架
- 采集代码里包含了大量与数据库的交互,不利于采集作为独立项目扩容部署至外网,同时一个脚本里做了所有的事情,采集,解析,数据库交互,消息传递,考虑职责解耦
- 代码中注释(结合需求文档)没有或非常少,包括程序运行间的日志记录,需要日志标准,统一日志组件
- 统一编码UTF-8,少用GBK
- 没有自动化发布以及部署机制(CICD)
采集主要涉及动作:数据库同步(聚合+转换)、API接口获取、网页获取(反而不多)
业务架构设计
(略)
未来架构设计
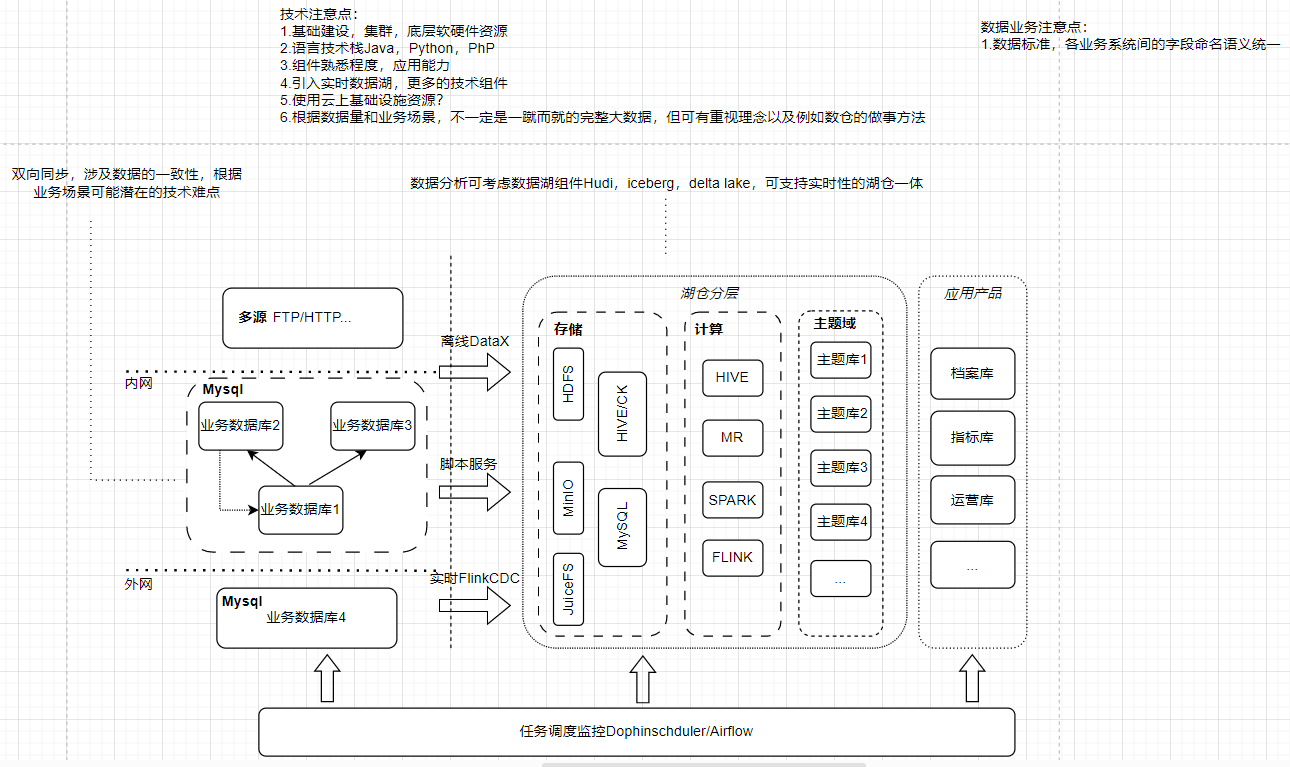
预期工作:
技术架构
- 工程标准: 代码工程化(采集框架、ETL框架) 推行Linux部署 分支管理 Gitlab CICD 数据库表设计命名规范 文档标准、日志标准
- 大数据运维: ELK搭建 Mysql监控
- 大数据平台: 寻找现成开源产品 串联各方服务 定义消息体来衔接
当前阶段实现
我们以原始/基础库的构建开始以达成我们的目标
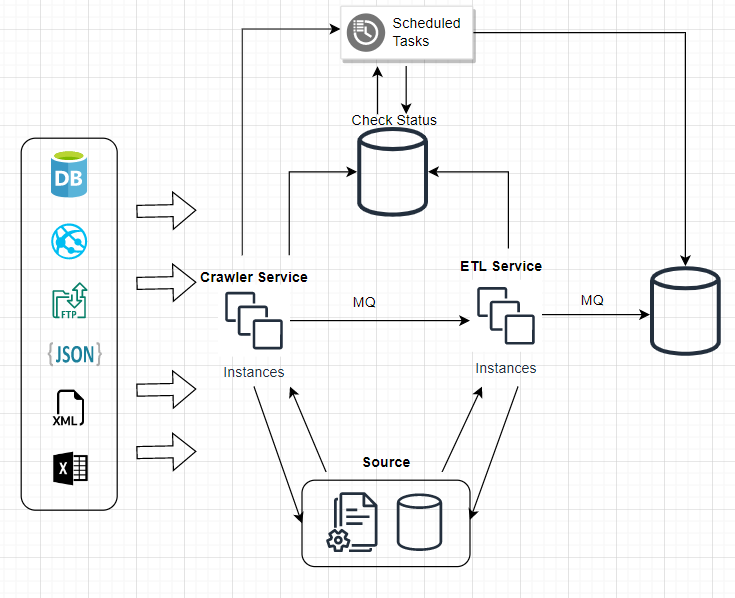

- Common Library
- Crawler Service
- ETL Service
能够做到:
- 每个独立的服务只继承于common接口
- 每个服务可以独立工作并且易于扩展
- 也能够共同组合完成一个完整的数据功能
Crawler Service:
- 易于扩展并支持更多的数据源
- 代理池支持
- 完整的日志为了debugging和状态检查
ETL Service:
- 框架支持插件式的集成各个数据源
- 自动化拆解解析器基于格式(HTML、XML、JSON,etc.)及元属性
- 提供统一的工具来支持清洗需求,比如标准字段的质量验证
Common Library:
- 统一的资源操作方法:数据库,文件系统
- 字典以及标准分类管理
- 统一工具中心:解压缩操作等
- 数据模型
模型设计
业务统一领域
阶段二
- 消息模型:支持以上服务能够串联操作并扩展
- 调度平台的搭建以及服务的集成
阶段三
- 数据库的转换同步,统一服务化并集成至调度平台
- 数据仓库的建设,数据服务的支持
阶段四
- 数据质量服务的集成以及可视化
数据业务治理设计
业务目标:
将基础数据作为一个公共服务 , 为用户提供公共数据服务支撑 , 帮助数据应用提升获取数据的效率 , 降低数据加工的深度和复杂度 : 提升各个产品和应用间数据的一致性。 主要包括以下几方面的内容 :
将业务系统数据同步进入到原始库 , 建立统一、一致 、 唯一的原始数据层 实现标准业务及应用层逻辑的加工和转换 。
技术目标:
在满足业务目标的同时 , 在数据模型设计上 , 重点关注以下目标 :
成本 : 模型设计者必须平衡性能和成本要素对数据模型的影响 , 尤其是 海量数据情况下 , 在保障业务和性能的前提下 , 应该使用合理的数据模型方案和 存储策略 , 尽量消除不必要的数据复制和冗余 。
性能 : 模型设计者需要兼顾模型刷新性能开销 、 产出时间和访问性能 。
数据一致性和数据互通 : 各个数据模型或者数据表之间保障数据输出的 一致性 , 相同粒度的相同数据项 ( 指标 、 维度 ) 具有相同的字段名称和业务描述 , 不同算法的业务指标应显性化区分 。
数据质量 : 数据模型需要屏蔽源头垃圾数据源 , 一方面要保障数据本身 的高质量 , 减少数据缺失 、 错误 、 异常等情况发生 : 另一方面需要保障其对应 业务元数据的高质量 , 数据有明确的业务含义 , 为数据使用者提供正确的指引 。
易用 : 在保障以上目标的前提下 , 数据用户能从业务角度出发快速找到 所需的数据 : 能较快的掌握模型的适用场景和使用方法 : 能相对便捷获取数据 。 但是 , 在目标出现冲突时 , 在通用数据模型并不完全承载用户使用数据的易用性目 标要求 , 数据消费产品和数据应用可以提升数据使用的易用性 。
设计原则:
公共处理逻辑下沉及单一 : 越是底层公用的处理逻辑更应该在数据调度 依赖的底层进行封装与实现 , 不要让公共的处理逻辑暴露给应用层实现 , 不要让公共逻辑在多处同时存在 。
可追溯性 : 处理逻辑不变 , 在不同时间多次运行数据结果确定不变 。
一致性 : 相同的字段在不同表字段名相同,命名清晰可理解。表命名规范需清晰 、 一致 , 表名需易于下游理解和使用。
成本与性能平衡 : 适当的数据冗余换取查询和刷新性能 , 不宜过度冗余 与数据复制 。
渠道管理
技术视角
人工上传、开放页面或接口、数据库清洗导入
业务视角
网站 公众号
数据模型及规范
来源原始数据集
标准化后基础数据集
以业务关系,或者事件过程为单位,建立模型(TODO)
数据处理规则
表字段关联规则
日期统一8位格式,比如20230531
数据编码标准
编码分类
代码集
数据质量标准
- 完整性
数据完整性分级(维度度量标准?以表级别、以实体域级别、以主题业务域级别,etc.)
完整性主要用于描述数据信息是否存在缺失数据记录或缺失数据项 。数据缺失的情况可能是整个数据记录缺失 , 也可能是数据中某个数据项的缺失 。
数据记录完整性:整个记录缺失 数据项完整性:数据记录中某些字段缺失
- 规范性
规范性指标主要用于评估数据内容与数据标准的符合度情况 · 一般来说包含格式合规性和值域有效性 。
格式合规性:类型、长度、精度、字段格式是否满足,比如:手机号11位,身份证号18位 值域有效性:字段值是否在规定范围内,比如在代码集范围内 准确性
准确性指标主要用于描述数据是否与其对应的客观实体的特征相一致 。 任何字段的数据 都应该符合特定的数据格式与值 。 准确性用于度量哪些数据和信息是不正确的 , 或者数据是 没有可用含义的 , 如果准确性指标无法满足 , 那么数据质量提供的数据就缺乏实际的业务使 用价值 。 比如人的年不应该是负数 , 概率数字应该在 0 和 1 之间取值 。
内容正确性:比如:结束日期不能小于开始日期,年龄不能小于0,出生日期和身份证一致 业务合理性:对账场景,企业许可证照不应该存在同一证照对应不同内容
- 唯一性
数据唯一性:数据全部或部分属性值应该确保唯一,比如企业注册号等
- 一致性
相同数据一致性:有相同字段在不同表中由于业务要求冗余存储时,保证数据的同步更新
- 及时性
版权声明:自由转载-非商用-非衍生-保持署名
comments powered by Disqus